
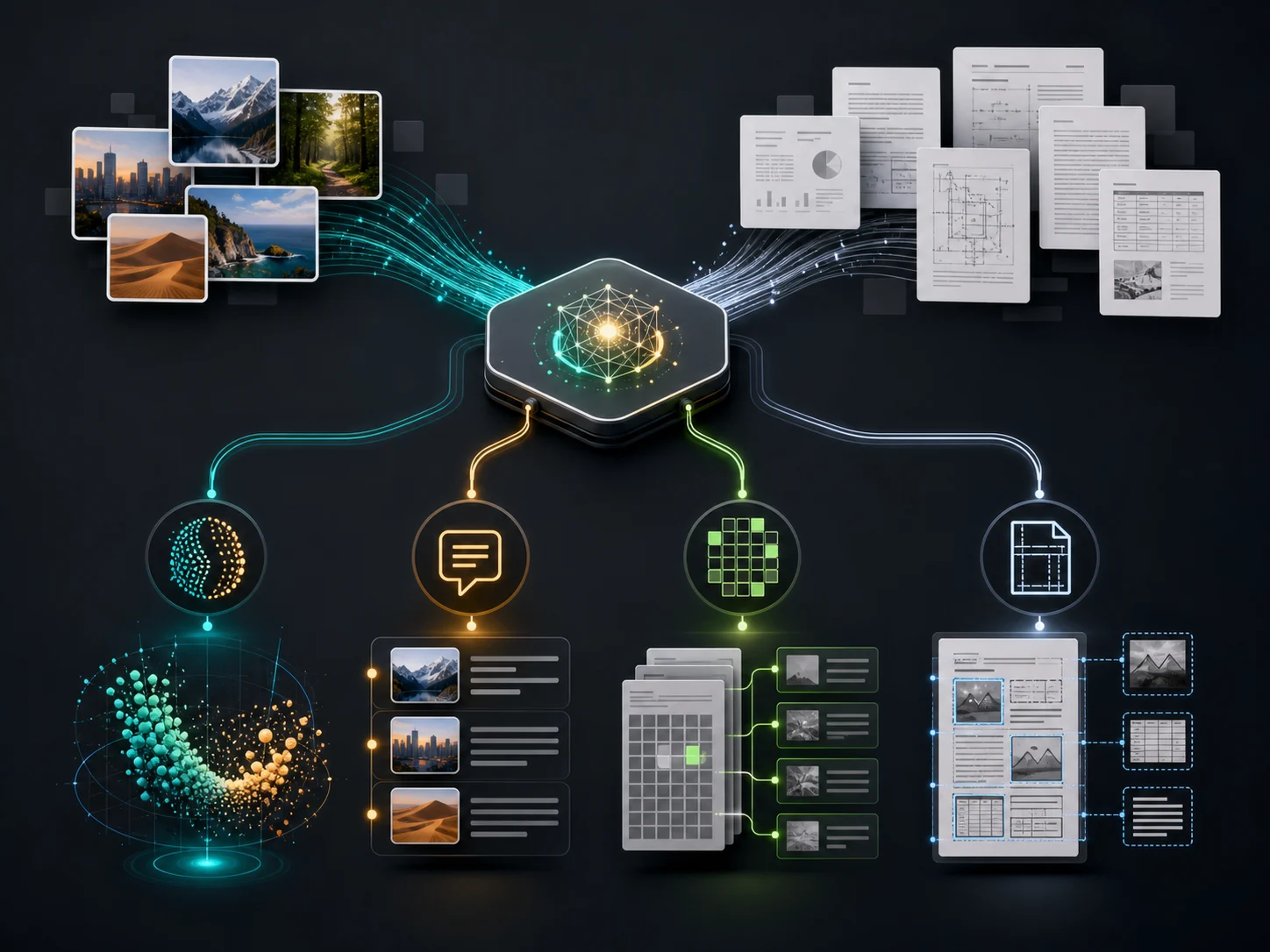
图像 RAG 工程实战(一):四种范式与模型选型
做文本 RAG,第一版长这样:文本 → 切块 → embedding → 向量库。做图像 RAG,很多团队的第一版直接套用这个心智模型——把图片丢给 CLIP,拿到一个向量,塞进同一个向量库——然后发现:扫描合同检索不出来、图表里的数字问不到、PDF 里的小字段全丢了。
问题出在一开始就把「图像 RAG」当成了一个问题。它其实是一类问题,至少要先分成两个截然不同的场景:
场景 A:自然图像 / 照片检索
电商商品图、相册、监控截图、UGC 图片
关注:图文语义对齐、以文搜图、以图搜图、相似图
场景 B:视觉富文档检索
PDF、扫描件、财报、论文、发票、PPT、网页截图
关注:版面、表格、图表、公式、小字、阅读顺序、引用回溯
这两类场景对应的技术栈、模型、向量库 schema、调参方法几乎完全不同。本系列三篇的主线是场景 B(视觉富文档)——因为这是 2025–2026 年进展最快、也最容易踩坑的方向——但场景 A 的方案会在选型里一并对比。
这是系列第一篇,只解决一个问题:面对一份具体的图像/文档数据,该选哪条技术路线、哪个模型。 调参和落地放在后两篇。
一、四种范式总览
把目前所有图像 RAG 方案归一下类,本质上只有四种范式。
四种范式的本质差异,在于**"图像信息在什么阶段、以什么形式被压成可检索的表示"**:
| 范式 | 检索表示 | 是否需要 OCR | 强项 | 软肋 |
|---|---|---|---|---|
| A 多模态 embedding | 单向量(图文同空间) | 否 | 以文搜图、跨模态、延迟低、存储省 | 细粒度文本/小字/表格弱 |
| B VLM 图注转文本 | 文本向量 | 否(VLM 隐式读图) | 复用现有文本 RAG、可解释 | 描述即有损、生成成本高、易漏信息 |
| C 视觉文档检索 | 多向量(每 patch 一向量) | 否 | 视觉富文档 SOTA、免版面解析 | 存储/延迟成本高(单页可达千级向量) |
| D OCR + 版面 | 结构化文本+坐标 | 是 | 精确文本/表格、引用回溯、合规可审计 | 解析是瓶颈、退化扫描件易错 |
一句话总结选型直觉:自然图像选 A;想复用文本栈、能接受有损选 B;视觉富文档优先 C;强合规/强表格/要逐字引用选 D 或 C+D 混合。 下面逐个拆开。
二、范式 A:多模态统一 Embedding
最经典的一条路线,源头是 CLIP:用图像编码器和文本编码器两个塔,通过对比学习把"猫的照片"和"a photo of a cat"拉到同一向量空间的邻近位置。检索时图和文用同一套向量、同一个索引,天然支持以文搜图、以图搜图、图文混排检索。
这条路线的工程优势非常实在:单向量、存储省、延迟低、向量库零特殊支持。代价是粒度——一张整页 PDF 被压成一个 768/1024 维向量,小字、表格行、图注这些细节会被"平均"掉。所以范式 A 是自然图像检索的默认选择,而不是密集文档检索的首选。
主流多模态 embedding 模型(按架构/可得性整理;具体检索分数随版本和数据集波动较大,落地前请用自己的评测集复测):
| 模型 | 开放方式 | 典型维度 | 语言 | 适合 | 备注 |
|---|---|---|---|---|---|
| CLIP (OpenAI) / OpenCLIP | 开放权重 | 512 / 768 | 英文为主 | 基线、原型、英文自然图 | 奠基之作,但对文本密集图像偏弱 |
| SigLIP / SigLIP2 (Google) | 开放权重 | 视配置 | SigLIP2 多语言 | 零样本分类/检索质量高 | sigmoid loss;SigLIP2 NaFlex 支持变分辨率 |
| jina-clip-v2 | 开放/商业 | 1024(可 MRL 截断) | 多语言(~89) | 多语言图文检索 | 支持 Matryoshka、512px 图像 |
| nomic-embed-vision-v1.5 | 开放权重 | 768 | 英文为主 | 与 nomic-embed-text 共享空间 | 文本侧/图像侧同空间,便于图文混检 |
| Cohere Embed v4 | API | 256/512/1024/1536(MRL) | 多语言 | 企业多模态、混排文档 | 单向量可直接编码含图文档,长上下文 |
| voyage-multimodal-3 | API | 1024 | 多语言 | 交错图文文档 | 文本与图像交错输入 |
| Chinese-CLIP | 开放权重 | 512/768 | 中文 | 中文自然图像、电商 | 中文图文对训练,中文场景明显优于原版 CLIP |
| BGE-VL (BAAI) | 开放权重 | 视配置 | 中英 | 组合图像检索、多模态 | 基于 MLLM,支持"图+改写指令"检索 |
值得单独点名 Jina Embeddings v4:它是 3.8B 参数、基于 Qwen2.5-VL-3B-Instruct 的"统一处理通路"模型(不是 CLIP 那种双塔),含 3 个各 60M 的任务专用 LoRA 适配器(非对称检索 / 对称相似 / 代码检索)。它同时提供两种输出——dense 单向量 2048 维(可经 MRL 截断到 128) 和 ColBERT 风格的多向量(128 维/token)。官方与论文报告,在视觉任务上多向量比单向量稳定高出约 7–10%(论文 Table 3 给出单向量 73.98 vs 多向量 80.55)。这等于把范式 A 和范式 C 装进了同一个模型,是当下"统一 embedding"路线最值得评估的代表。[¹][²]
中文自然图像:优先 Chinese-CLIP 或 BGE-VL,再用自己的数据集对比 jina-clip-v2 / SigLIP2 的多语言表现。
三、范式 B:VLM 图注转文本
思路最朴素:用一个视觉语言模型(VLM)把图像/页面"读"成一段文字描述或结构化摘要,然后完全复用现有的文本 RAG 栈。
它的吸引力在于:团队已有的文本 RAG(切块、BM25、rerank、引用)一行不改就能用,且生成的描述天然可读、可审计。常用 VLM:
| VLM | 开放方式 | 适合 | 备注 |
|---|---|---|---|
| Qwen2.5-VL | 开放权重(多尺寸) | 中英文档、表格、图表、可本地部署 | 中文场景与可控成本的首选开源 VLM |
| GPT-4o / 4.1 | API | 高质量通用图像理解 | 质量高但单价与延迟需控量 |
| Gemini 2.x | API | 长文档、多页、超长上下文 | 适合一次性读整本 PDF |
| InternVL | 开放权重 | 高分辨率文档、OCR-heavy | 开源高分辨率方向强 |
| MiniCPM-V | 开放权重 | 端侧/轻量、单图理解 | 体积小、可边缘部署 |
范式 B 的致命软肋是**"描述即有损"**:VLM 把一张信息密度极高的财报页压成 300 字摘要时,必然丢掉大量原始数字和版面关系。一旦用户问的恰好是被丢掉的那个数字,再强的检索也救不回来。此外,对海量文档逐页跑 VLM 生成描述,离线索引成本(GPU 时 / API 费用)会非常高。
何时用 B:图像数量有限、需要强文本推理与可解释摘要、且已有成熟文本 RAG 不想推倒重来。何时别用 B:百万页级文档库、或问题高度依赖原文逐字细节。
四、范式 C:视觉文档检索(late-interaction 多向量)
这是 2024 年 ColPali 论文开创、目前在视觉富文档检索(ViDoRe 类基准)上的 SOTA 范式,也是本系列的重点。
核心机制一句话:不做 OCR、不做版面解析,直接把整页截图喂给 VLM 的视觉塔,把 ViT 输出的每一个 patch 经线性投影成一个 128 维向量,得到"每页一组多向量";检索时用 MaxSim 做晚交互(late interaction)打分。 [³][⁴]
MaxSim 的直觉是:对查询里的每一个 token 向量,去文档的所有 patch 向量里找最相似的那个,再把这些最大相似度加总。这让模型能把"查询里的某个词"精确对齐到"页面上的某一块区域"——表格的某个单元格、图表的某条曲线、某行小字——这正是单向量范式 A 做不到的细粒度。
ColPali 衍生出了一整个 ColVision 家族,覆盖不同 VLM 骨干、许可证差异很关键(要商用务必看清):
| 模型 | 骨干 | 参数量 | 许可证 | 备注 |
|---|---|---|---|---|
| ColPali v1.3 | PaliGemma-3B | 3B | Gemma(有使用条款) | 开山之作 |
| ColQwen2 v1.0 | Qwen2-VL-2B | 2B | Apache 2.0 | 商用友好,HF cookbook 默认 |
| ColQwen2.5 v0.2 | Qwen2.5-VL-3B | 3B | Apache 2.0 | 新一代骨干 |
| ColSmol-256M | SmolVLM-256M | 256M | Apache 2.0 | 极轻量,边缘/低显存 |
训练型视觉文档嵌入模型里,目前最强者之一是 ColNomic-embed-multimodal-7B(基于 Qwen2.5-VL-7B-Instruct 微调、统一编码交错图文)。官方 model card 报告其在 ViDoRe-v2 上 62.7 NDCG@5,领先 ColNomic-3B(61.2)、T-Systems ColQwen2.5-3B(59.9)、Nomic Embed Multimodal-7B(59.7)、GME-Qwen2-7B(59.0)。注意这是厂商自报的同类对比表,落地前应在自己的数据上复测。[⁵]
范式 C 的代价非常具体,也是后两篇要解决的核心工程问题:多向量极占空间。ColPali 单页可生成约 1030 个向量、约 256KB——直接全量存储,百万页就是 256GB 的向量。怎么在不显著掉点的前提下把这个成本压下来(两阶段检索、量化、池化),是第二篇的主题。[⁶]
五、范式 D:OCR + 版面解析混合
范式 C 虽然在很多基准上领先,但它不是银弹。当文档需要逐字精确的文本、严格的表格结构、可审计的引用回溯,或扫描质量很差时,传统的 OCR + 版面解析 仍然有不可替代的价值——它产出的是结构化、可定位、可逐字核对的文本。
常用工具(按定位整理):
| 工具 | 定位 | 强项 | 备注 |
|---|---|---|---|
| PaddleOCR | OCR + 版面 + 表格 | 中文成熟、生态全、可本地 | 中文文档检测/识别的稳妥基线 |
| GOT-OCR2.0 | 端到端 OCR | 公式、表格、乐谱等统一 OCR | 复杂版式一体化识别 |
| dots.ocr | 版面+识别一体 | 多语言、版面与文本联合 | 较新,适合做候选评测 |
| Surya | OCR + 版面 + 阅读顺序 | 多语言、版面与阅读顺序 | 轻量、易集成 |
| MinerU / Docling | 文档转 Markdown/JSON | 复杂 PDF → LLM-ready | 第一篇 RAG 成熟度系列已详述 |
文献已经暗示一个重要事实:在文本密度极高或扫描退化的文档上,OCR 路线有时反而比纯视觉检索更准。但目前缺乏定量的"切换阈值"——这正是该领域的开放问题之一。务实做法是:把 D 当作 C 的补充而非替代,对关键文档同时建 C(视觉多向量)和 D(结构化文本)两路索引,用第二篇会讲的混合检索融合。
六、选型决策树
把上面四条路线收敛成一棵可执行的决策树:
再给一张按场景落地的对照表:
| 场景 | 首选范式 | 推荐起步模型 | 向量库 |
|---|---|---|---|
| 电商/相册自然图检索 | A | Chinese-CLIP(中)/ SigLIP2(多语言) | 单向量 HNSW(任意主流库) |
| 中小规模视觉富文档问答 | C | ColQwen2.5 / Jina v4(多向量) | Qdrant / Milvus 多向量 |
| 百万页级文档库 | C + 工程优化 | ColQwen2 + 两阶段+量化 | Vespa / Milvus / Qdrant |
| 财报/合同(要逐字引用) | C + D | ColQwen + PaddleOCR/MinerU | 多向量 + 结构化文本双路 |
| 已有成熟文本 RAG、图像不多 | B | Qwen2.5-VL 图注 | 复用现有文本向量库 |
七、中文场景的特别说明
必须诚实:在本轮调研里,中文多模态模型(Chinese-CLIP、BGE-VL)以及 Qwen2.5-VL 系骨干对中文版面/表格的检索表现,缺乏经独立核验的公开基准。这不代表它们不行,而是没有可直接引用的权威数字。务实建议:
- 中文自然图像:Chinese-CLIP 起步,BGE-VL 做组合检索候选;
- 中文视觉富文档:ColQwen2.5(Qwen2.5-VL 骨干,对中文 OCR 友好)做范式 C 主力,PaddleOCR 做范式 D 补充;
- 务必自建中文评测集:不要照搬英文 ViDoRe 的结论。中文的字间距、竖排、繁简、表格密度都会改变排名。第三篇会给出离线评测集的搭建方法。
小结与下一篇
本篇把"图像 RAG"从一个含糊的需求,拆成了两类场景 × 四种范式,并给出了可执行的选型决策树。一句话收尾:
自然图像看范式 A;视觉富文档优先范式 C(ColPali 系 late-interaction),强合规叠加范式 D(OCR),图像不多且要可读性时用范式 B。
选好了路线,真正的工程难题才开始:范式 C 的多向量动辄单页上千、单页 256KB,怎么把存储和延迟压到可生产?**第二篇《检索与调参》**会逐一拆解:图像分辨率/patch、Matryoshka 维度截断、MaxSim 与 top-k、两阶段检索(13x 提速)、binary/int8 量化(最高 64x 压缩)、以及 HNSW/IVF 索引参数,并给出一张调参速查表。
参考资料
- Jina Embeddings v4 公告
- Jina Embeddings v4 论文 (arXiv 2506.18902)
- ColPali GitHub (illuin-tech/colpali)
- ColPali 论文 (arXiv 2407.01449)
- ColNomic-embed-multimodal-7B Model Card
- Qdrant: Optimizing ColPali for Production
- Vespa: The Rise of Vision-Driven Document Retrieval for RAG
- HuggingFace Cookbook: Multimodal RAG with Document Retrieval + Reranker + VLMs