
图像 RAG 工程实战(三):可落地架构与参考实现
前两篇定了路线(范式 C:视觉文档 late-interaction)和参数(两阶段检索 + 量化)。这一篇只回答一个问题:怎么把它变成能跑、能部署、能评测的系统。 所有代码尽量贴近可直接运行的状态,关键链路标注来源。
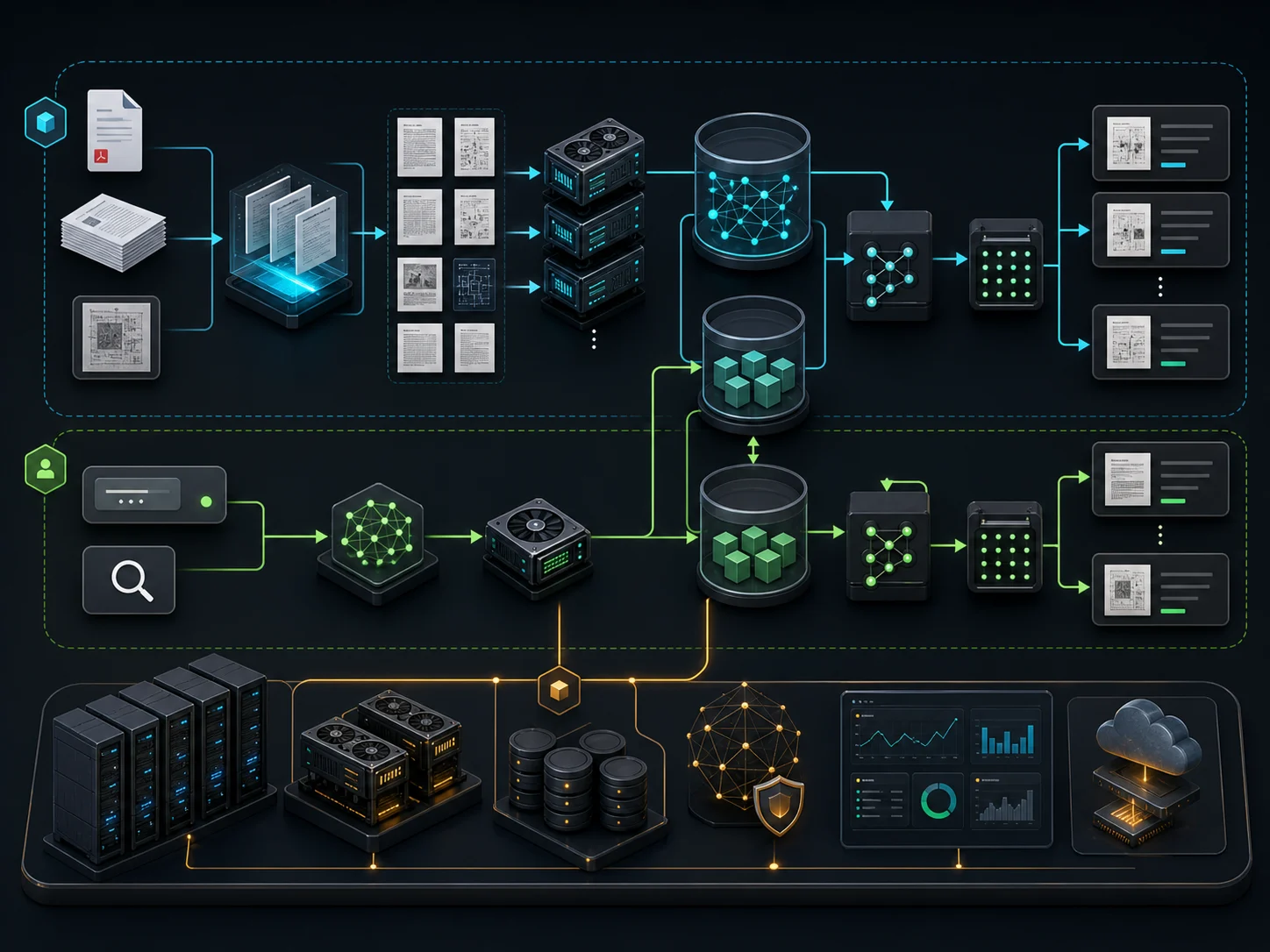
一、整体架构
一个生产级视觉文档 RAG,逻辑上分两条流水线:离线索引和在线查询。
组件清单与选型:
| 组件 | 推荐起步 | 说明 |
|---|---|---|
| 文档渲染 | pdf2image + Poppler | PDF → 每页 PNG |
| 视觉检索编码 | ColQwen2.5 v0.2 (Apache 2.0) | 多向量 embedding |
| 检索框架 | Byaldi(快速原型)/ 原生 colpali-engine(可控) | 见第二、三节 |
| 多向量库 | Qdrant 或 Milvus | 原生 MaxSim 多向量 |
| 重排 | MonoQwen2-VL-v0.1 | 视觉文档 pointwise reranker |
| 生成 VLM | Qwen2.5-VL(vLLM 服务化) | 读图回答 + 引用 |
二、最快跑通:Byaldi 三行索引
想在一小时内验证可行性,用 Byaldi(ColPali 系的高层封装):
# pip install byaldi pdf2image
from byaldi import RAGMultiModalModel
# 加载 ColQwen2(Apache 2.0,HF cookbook 默认)
RAG = RAGMultiModalModel.from_pretrained("vidore/colqwen2-v1.0")
# 索引一个目录下的所有 PDF:自动渲染成图像 + 编码多向量 + 建索引
RAG.index(
input_path="docs/",
index_name="my_docs",
store_collection_with_index=True, # 把页面图像 base64 一起存,方便后续喂 VLM
overwrite=True,
)
# 检索:直接返回 top-k 页(含页码、文档名、可选 base64 图像)
results = RAG.search("2025 年第三季度毛利率是多少?", k=5)
for r in results:
print(r.doc_id, r.page_num, r.score)
Byaldi 适合 PoC 和中小库。要做生产级的两阶段检索、量化、外部向量库,就需要下一节的原生路径。
三、可控路径:原生 colpali-engine + 外部多向量库
3.1 编码与 MaxSim 打分
# pip install colpali-engine torch pdf2image
import torch
from pdf2image import convert_from_path
from colpali_engine.models import ColQwen2, ColQwen2Processor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = ColQwen2.from_pretrained(
"vidore/colqwen2-v1.0",
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
processor = ColQwen2Processor.from_pretrained("vidore/colqwen2-v1.0")
# 1) 文档侧:PDF -> 页面图像 -> 多向量
pages = convert_from_path("report.pdf", dpi=150)
with torch.no_grad():
batch = processor.process_images(pages).to(device)
doc_embeddings = model(**batch) # list[Tensor[num_patches, 128]]
# 2) 查询侧:文本 -> query token 向量
with torch.no_grad():
q_batch = processor.process_queries(["2025 年第三季度毛利率"]).to(device)
query_embeddings = model(**q_batch) # Tensor[num_q_tokens, 128]
# 3) MaxSim 晚交互打分(processor 内置,等价于第二篇手写的 max_sim)
scores = processor.score_multi_vector(query_embeddings, doc_embeddings)
top = scores[0].topk(5)
print(top.indices.tolist(), top.values.tolist())
这套"ColQwen2 检索 + 量化 VLM 生成"的端到端管线,HuggingFace 官方 cookbook 验证可在单张消费级 GPU(NVIDIA L4,显存 < 24GB) 跑通,并明确以视觉文档检索模型替代了传统 OCR 管线。[¹]
3.2 写入 Qdrant(原生多向量 + binary 量化)
Qdrant 原生支持多向量 MaxSim,并能直接开 binary 量化:
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="visual_docs",
vectors_config=models.VectorParams(
size=128,
distance=models.Distance.COSINE,
# 多向量 + MaxSim 晚交互
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
# binary 量化(配合 rescoring,见第二篇 5.1)
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(always_ram=True)
),
),
)
# 每页一个 point,payload 里带页码用于引用回溯
points = [
models.PointStruct(
id=i,
vector=emb.cpu().float().numpy().tolist(), # [num_patches, 128]
payload={"doc": "report.pdf", "page": i + 1},
)
for i, emb in enumerate(doc_embeddings)
]
client.upsert(collection_name="visual_docs", points=points)
# 查询:oversampling + rescoring 用 float32 救回精度
hits = client.query_points(
collection_name="visual_docs",
query=query_embeddings[0].cpu().float().numpy().tolist(),
limit=10,
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(rescore=True, oversampling=4.0)
),
).points
3.3 Milvus 多向量混合检索(dense + sparse 融合)
如果要把范式 C(视觉多向量)和范式 D(OCR 文本的 sparse/BM25)做混合,Milvus 是顺手的选择:每集合默认 4 个向量字段、可改 proxy.maxVectorFieldNum 到最多 10,混合检索并行跑多路 ANN,再用 WeightedRanker(分数加权)或 RRFRanker(按排名做 Reciprocal Rank Fusion) 融合。[²]
from pymilvus import MilvusClient, AnnSearchRequest, WeightedRanker
client = MilvusClient(uri="http://localhost:19530")
# 一个集合里同时放:视觉多向量(粗排表示) + 文本稀疏向量(OCR/BM25)
req_visual = AnnSearchRequest(
data=[pooled_query_vec], anns_field="visual_pooled",
param={"metric_type": "IP", "params": {"ef": 128}}, limit=200,
)
req_text = AnnSearchRequest(
data=[sparse_query_vec], anns_field="text_sparse",
param={"metric_type": "IP"}, limit=200,
)
res = client.hybrid_search(
collection_name="docs",
reqs=[req_visual, req_text],
ranker=WeightedRanker(0.7, 0.3), # 视觉 0.7 / 文本 0.3;或换 RRFRanker(k=60)
limit=50,
output_fields=["doc", "page"],
)
Weaviate 也是可选项:v1.29 起原生支持 ColBERT/ColPali/ColQwen 多向量 + MaxSim,v1.30 GA,v1.31 加入 MUVERA(把多向量编码成单向量以复用常规 ANN)。[³] Vespa 则有把 ColPali 扩到十亿级的公开方案。本轮调研未对 pgvector/LanceDB 的 ColBERT-style 原生支持成熟度做核验,选型前请查最新文档。
四、重排与生成
4.1 MonoQwen2-VL 重排
对精排后的 Top-50 再做一层 VLM pointwise 重排,提升头部精度:
# MonoQwen2-VL-v0.1:首个视觉文档 reranker (Qwen2-VL-2B LoRA)
from transformers import AutoProcessor, AutoModelForVision2Seq
import torch
rr_proc = AutoProcessor.from_pretrained("lightonai/MonoQwen2-VL-v0.1")
rr_model = AutoModelForVision2Seq.from_pretrained(
"lightonai/MonoQwen2-VL-v0.1", torch_dtype=torch.bfloat16, device_map="cuda"
).eval()
def rerank(query: str, page_images: list, top_k: int = 10):
scored = []
for img in page_images: # 对每个候选页打 relevance 分
prompt = (f"Assert the relevance of the previous image document to "
f"the following query: {query}. Answer True or False.")
inputs = rr_proc(text=prompt, images=img, return_tensors="pt").to("cuda")
with torch.no_grad():
logits = rr_model(**inputs).logits[:, -1, :]
true_id = rr_proc.tokenizer.convert_tokens_to_ids("True")
scored.append(torch.softmax(logits, -1)[0, true_id].item())
order = sorted(range(len(page_images)), key=lambda i: -scored[i])
return order[:top_k]
MonoQwen2-VL 论文报告 ViDoRe ndcg@5 达 90.5,是这一段重排的强基线。[⁴]
4.2 用 VLM 读图生成带引用的答案
把重排后的 Top-K 页图像直接喂给生成 VLM:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
gen_proc = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
gen_model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="cuda"
)
def generate(query: str, top_pages: list):
content = [{"type": "image", "image": img} for img in top_pages]
content.append({"type": "text",
"text": f"基于上述页面回答,并在答案末尾标注信息来自第几页:{query}"})
messages = [{"role": "user", "content": content}]
text = gen_proc.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = gen_proc(text=[text], images=top_pages, return_tensors="pt").to("cuda")
out = gen_model.generate(**inputs, max_new_tokens=512)
return gen_proc.batch_decode(out, skip_special_tokens=True)[0]
引用回溯:因为每页 point 的 payload 里存了 {doc, page},答案可以精确标注"来自 report.pdf 第 12 页"——这是视觉文档 RAG 相对"图注转文本"范式的一大可解释性优势。
五、服务化部署
生产环境不要把 VLM 塞进请求进程,用 vLLM 起独立推理服务:
# 生成 VLM 服务(OpenAI 兼容接口)
vllm serve Qwen/Qwen2.5-VL-7B-Instruct \
--port 8000 \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--limit-mm-per-prompt image=8 # 限制单次最多 8 张图,控显存
部署拓扑(与你工作区的单机/多容器风格一致):
落地提醒(针对单机服务器):ColQwen 编码、VLM 重排、VLM 生成都需要 GPU;纯 CPU 的云主机(如未挂卡的腾讯云 CVM)跑不动范式 C。务实方案有三:① 单独挂一台 GPU 实例只跑这三个服务,向量库和编排 API 留在现有服务器;② 编码/生成走云端 VLM API、只自建向量库与编排;③ 用 ColSmol-256M 这类极轻量模型在小显存上做降级版。
六、GPU 选型与成本权衡
| 配置 | 检索模型 | 生成 VLM | 显存档位 | 适用 |
|---|---|---|---|---|
| 入门(已验证) | ColQwen2-2B | 量化 Qwen2-VL | 单张 L4 < 24GB [¹] | PoC、中小库 |
| 标准 | ColQwen2.5-3B | Qwen2.5-VL-7B | ~24–48GB(如 L40S/A100-40G) | 生产主力 |
| 高精度 | ColNomic-7B | Qwen2.5-VL-32B+ | 多卡 / A100-80G 级 | 高难文档、研究 |
| 降级(小显存) | ColSmol-256M | 云端 VLM API | < 12GB | 边缘 / 成本敏感 |
成本权衡的三条经验:
- 离线索引是大头:百万页逐页编码的 GPU 时,往往比在线查询贵得多。优先把索引做成可断点续跑的批处理。
- 存储用量化换:binary+rescoring 直接把向量存储降到 1/32(见第二篇),是省钱最快的旋钮。
- 生成按需降配:检索+重排定生死,生成模型可以先用 7B,质量不够再升级,不必一上来就上 32B。
注意:表中显存档位除"入门(L4 < 24GB)"为官方 cookbook 实测外,其余为按参数量估算的级别,非基准实测——上线前请以实际权重精度(bf16/量化)和 batch 实测为准。
七、离线评测:不评测就别上生产
视觉文档 RAG 的检索质量必须离线量化,沿用信息检索标准指标 NDCG@k / Recall@k。最小评测集结构:
评测集(每条样本):
query 自然语言问题
relevant_pages 该问题的标准答案所在页(doc_id + page_num),可多页
指标:
NDCG@5 / NDCG@10 头部排序质量
Recall@10 / @20 正确页是否进了候选
分桶:文本密集 / 表格 / 图表 / 扫描退化 / 中文竖排 …
一个无依赖的 NDCG@k 参考实现:
import numpy as np
def ndcg_at_k(ranked_page_ids: list, relevant: set, k: int = 5) -> float:
"""ranked_page_ids: 检索返回的页 id 列表(已按分数降序)"""
gains = [1.0 if pid in relevant else 0.0 for pid in ranked_page_ids[:k]]
dcg = sum(g / np.log2(i + 2) for i, g in enumerate(gains))
ideal = sorted([1.0] * min(len(relevant), k), reverse=True)
idcg = sum(g / np.log2(i + 2) for i, g in enumerate(ideal))
return dcg / idcg if idcg > 0 else 0.0
def evaluate(eval_set, retrieve_fn, k=5):
scores = [ndcg_at_k(retrieve_fn(s["query"]), set(s["relevant_pages"]), k)
for s in eval_set]
return float(np.mean(scores))
强烈建议:中文文档务必自建中文评测集,不要照搬英文 ViDoRe 的排名结论(第一篇已强调)。按文档类型分桶评测,才能定位是表格、扫描质量还是版式拖了后腿。
八、生产上线清单
[ ] 选型:已按第一篇决策树确认范式(C / C+D / B)
[ ] 评测集:≥ 数百条 query,按文档类型分桶,含"无答案"负例
[ ] 索引:可断点续跑的批处理;记录每页向量数与存储量
[ ] 量化:binary + rescoring 已开;抽样比对量化前后 NDCG
[ ] 两阶段:mean-pool 粗排 + 全分辨率精排(确认用 mean 不是 max)
[ ] 重排:MonoQwen2-VL 在高精度场景已接入并 A/B
[ ] 服务化:VLM 走 vLLM 独立服务;限制单请求图像数控显存
[ ] 引用:答案带 doc_id + page_num,可回溯原页
[ ] 监控:检索延迟 P95、召回、生成 token 成本、GPU 利用率
[ ] 降级:GPU 不可用时的云端 API / ColSmol 降级路径
九、踩坑与时效性提醒
把本系列调研中被对抗式核验否决、不可引用的说法集中标注,避免你被网上流传的数字误导:
- ❌ Jina v4 的 ViDoRe 90.17 / Jina-VDR 84.11 nDCG@5(被否,0-3);
- ❌ HPC-ColPali"注意力剪枝削减 60% 计算、<2% nDCG 损失"(被否,0-3);
- ❌ HPC-ColPali"HNSW 下降低 30–50% 延迟"(被否,0-3);
- ❌ ColVision 各模型 ViDoRe leaderboard 的精确分数(如 ColQwen2.5 89.4,1-2 未通过),不要当精确选型依据。
以及两条全局注意:
- 时效性:本系列锚定 2025 年中至 2026-06 的快照。视觉文档检索迭代极快(ViDoRe 已出 V3、新骨干层出不穷),落地前务必核对各模型与向量库的最新版本与基准。
- 厂商自报基准:Qdrant 的 13x、ColNomic 的对比表、Jina 的 7–10% 多向量优势、32x/64x 压缩与 90%/95–96% 精度保留,多为 best-case 或单基准自报。方向上有同行评审佐证,但绝对值不要外推到你的数据——以自建评测集复测为准。
系列结语
三篇下来,我们走完了图像 RAG 的完整工程链路:
第一篇 把"图像 RAG"拆成两类场景、四种范式,给出选型决策树;第二篇 拆解范式 C 的成本难题,用两阶段检索(13x)和量化(最高 64x)把它压到可生产;第三篇 把方案落成可运行代码、可部署架构、可量化评测。
一句话收尾:视觉富文档 RAG 已经不需要把 PDF "拆成文本"了——直接让模型"看页面",用 late-interaction 多向量检索,再用工程手段把成本压下来,是 2026 年最值得落地的一条路线。 但任何选型都要回到同一个铁律:先有评测集,再谈最先进。
参考资料
- HuggingFace Cookbook: Multimodal RAG(ColQwen2 + MonoQwen2-VL + 量化 VLM,单张 L4 跑通)
- Milvus 多向量混合检索(WeightedRanker / RRFRanker,最多 10 向量字段)
- Weaviate 多向量 Embeddings(ColBERT/ColPali/ColQwen + MaxSim)
- MonoQwen2-VL-v0.1(视觉文档 reranker,ViDoRe ndcg@5 90.5)
- Qdrant: Optimizing ColPali for Production
- Vespa: Scaling ColPali to Billions
- ColPali GitHub(colpali-engine / Byaldi 生态)
- HuggingFace: Embedding Quantization